Flattening
Swipe to show menu
Transitioning from Feature Extraction to Classification
After convolutional and pooling layers extract essential features from an image, the next step in a convolutional neural network (CNN) is classification. Since fully connected layers require a one-dimensional input, we need to convert the multidimensional feature maps into a format suitable for classification.
Converting Feature Maps into a 1D Vector
Flattening is the process of reshaping the output of convolutional and pooling layers into a single long vector. If a feature map has dimensions X × Y × Z, flattening transforms it into a 1D array of length X × Y × Z.
For example, if the final feature map has dimensions 7 × 7 × 64, flattening converts it into a (7 × 7 × 64) = 3136-dimensional vector. This allows the fully connected layers to process the extracted features efficiently.
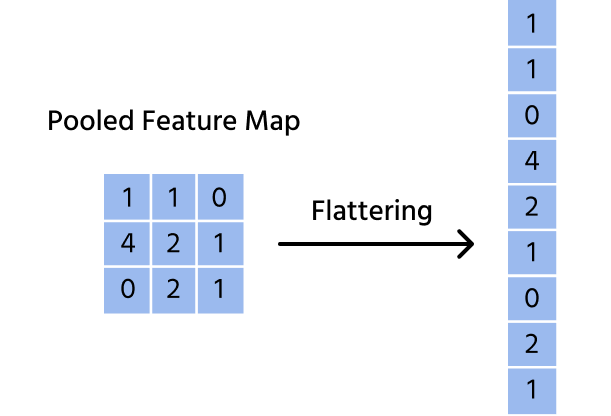
Importance of Flattening Before Feeding into Fully Connected Layers
Fully connected layers operate on a standard neural network structure, where each neuron connects to every neuron in the next layer. Without flattening, the model cannot interpret the spatial structure of the feature maps correctly. Flattening ensures:
- Proper transition from feature detection to classification;
- Seamless integration with fully connected layers;
- Efficient learning by preserving extracted patterns for final decision-making.
By flattening the feature maps, CNNs can leverage high-level features learned during convolution and pooling, enabling accurate classification of objects within an image.
1. Why is flattening necessary in a CNN?
2. If a feature map has dimensions 10 × 10 × 32, what will be the size of the flattened output?
Thanks for your feedback!
Ask AI
Ask AI

Ask anything or try one of the suggested questions to begin our chat
