Overview of Popular CNN Models
Swipe to show menu
Convolutional neural networks (CNNs) have significantly evolved, with various architectures improving accuracy, efficiency, and scalability. This chapter explores five key CNN models that have shaped deep learning: LeNet, AlexNet, VGGNet, ResNet, and InceptionNet.
LeNet: The Foundation of CNNs
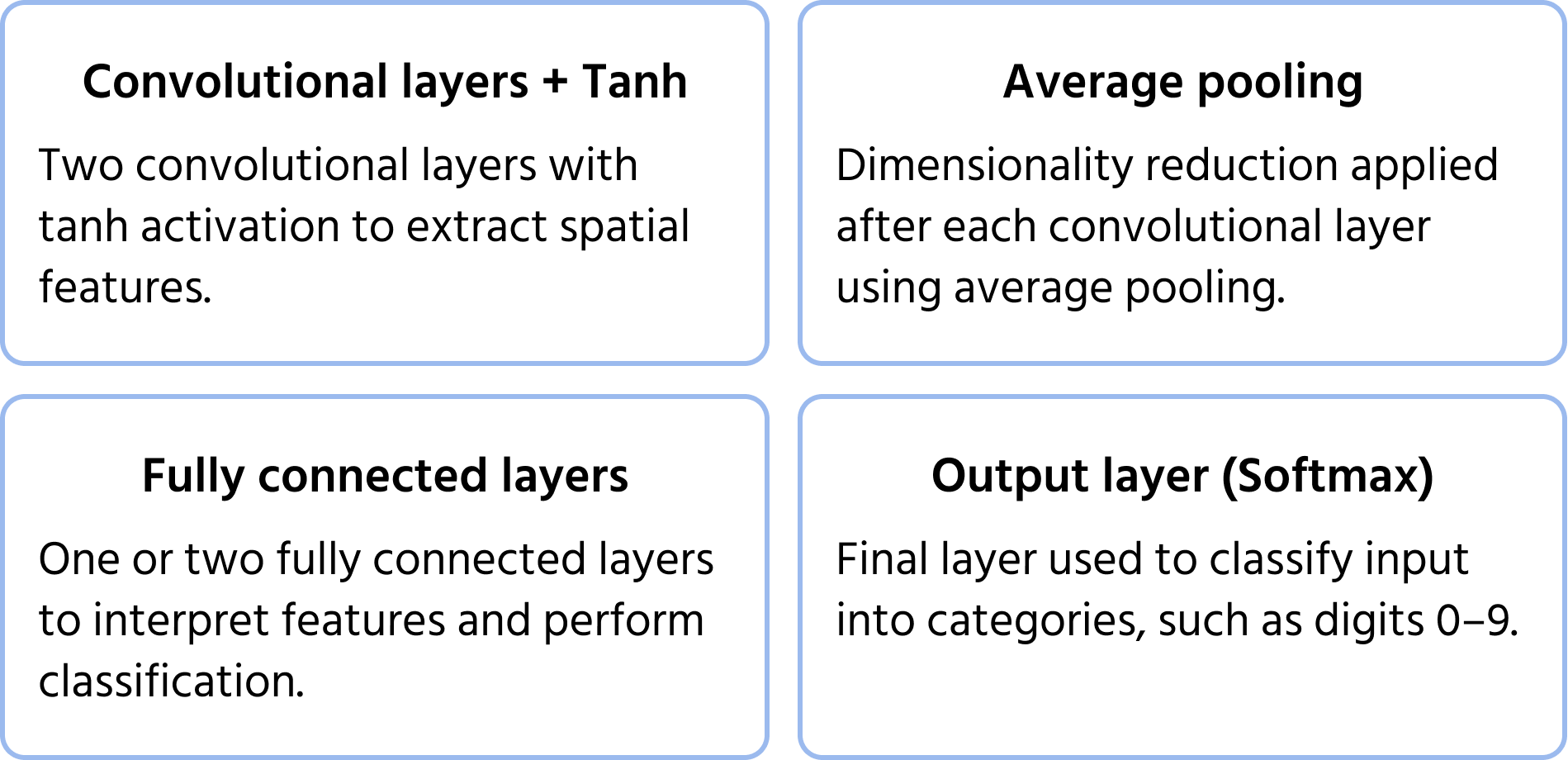
One of the first convolutional neural network architectures, proposed by Yann LeCun in 1998 for handwritten digit recognition. It laid the foundation for modern CNNs by introducing key components like convolutions, pooling, and fully connected layers. You can learn more about the model in the documentation.
Key Architecture Features
AlexNet: Deep Learning Breakthrough
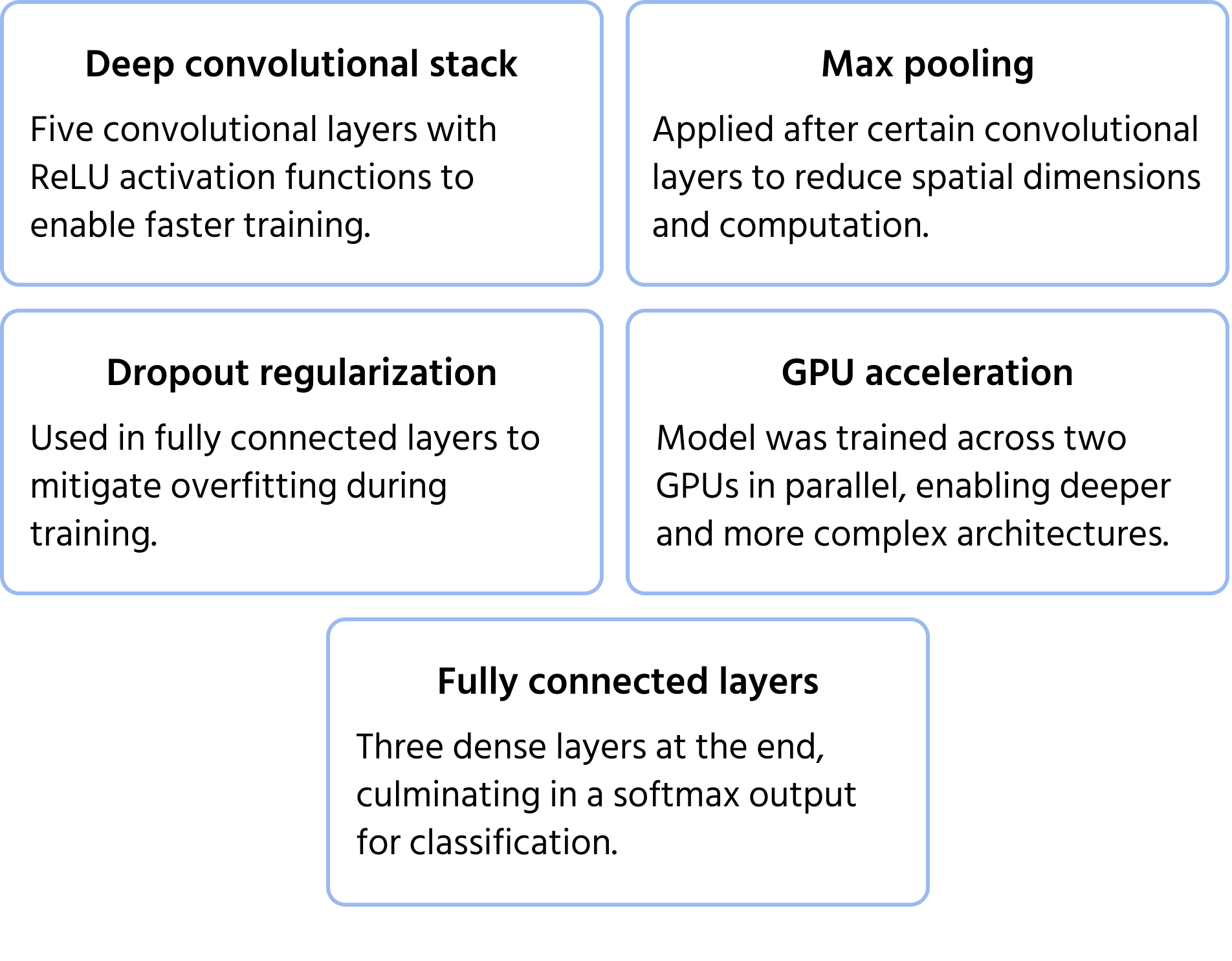
A landmark CNN architecture that won the 2012 ImageNet competition, AlexNet proved that deep convolutional networks could significantly outperform traditional machine learning methods for large-scale image classification. It introduced innovations that became standard in modern deep learning. You can learn more about the model in the documentation.
Key Architecture Features
VGGNet: Deeper Networks with Uniform Filters
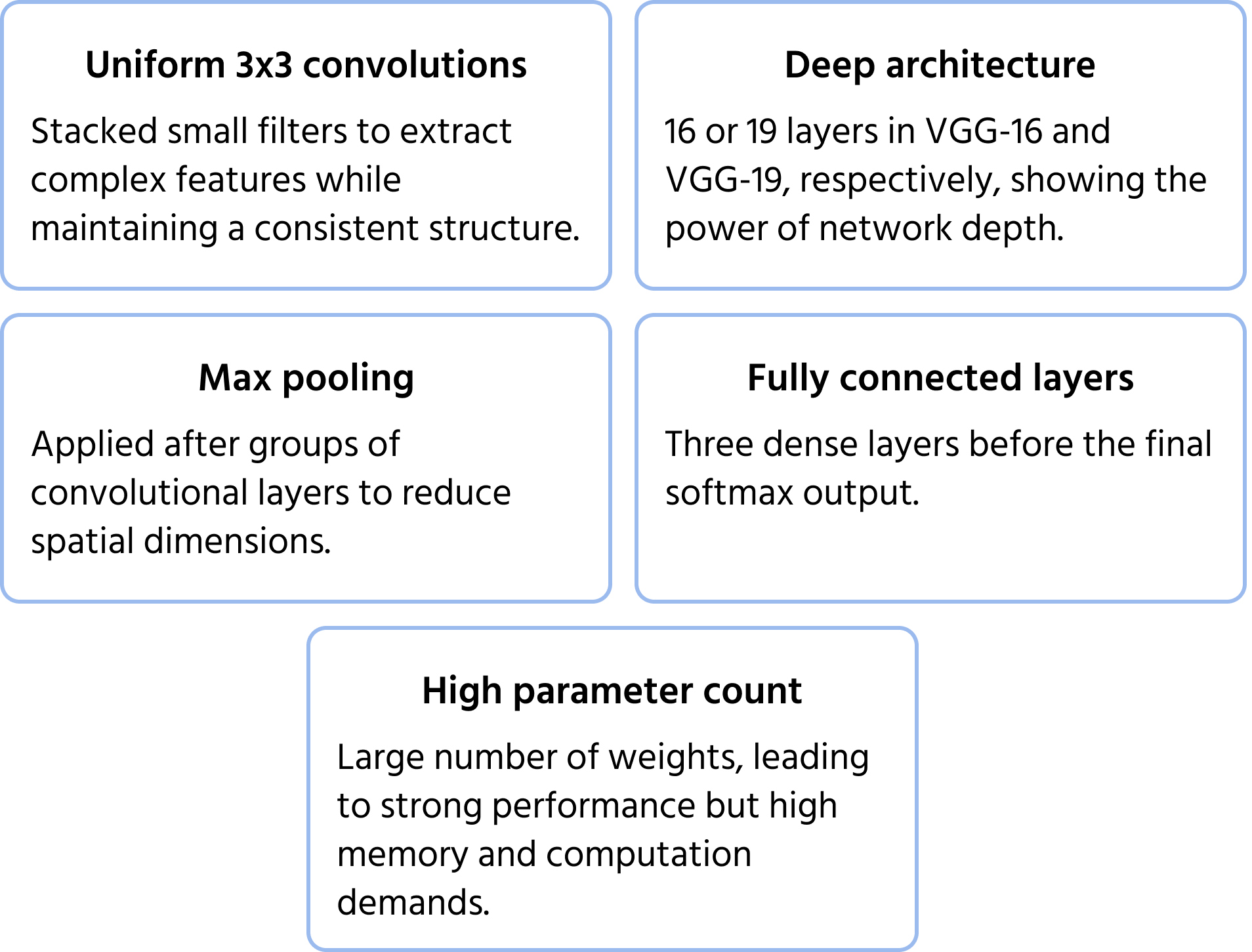
Developed by the Visual Geometry Group at Oxford, VGGNet emphasized depth and simplicity by using uniform 3×3 convolutional filters. It showed that stacking small filters in deep networks could significantly enhance performance, leading to widely used variants like VGG-16 and VGG-19. You can learn more about the model in the documentation.
Key Architecture Features
ResNet: Solving the Depth Problem
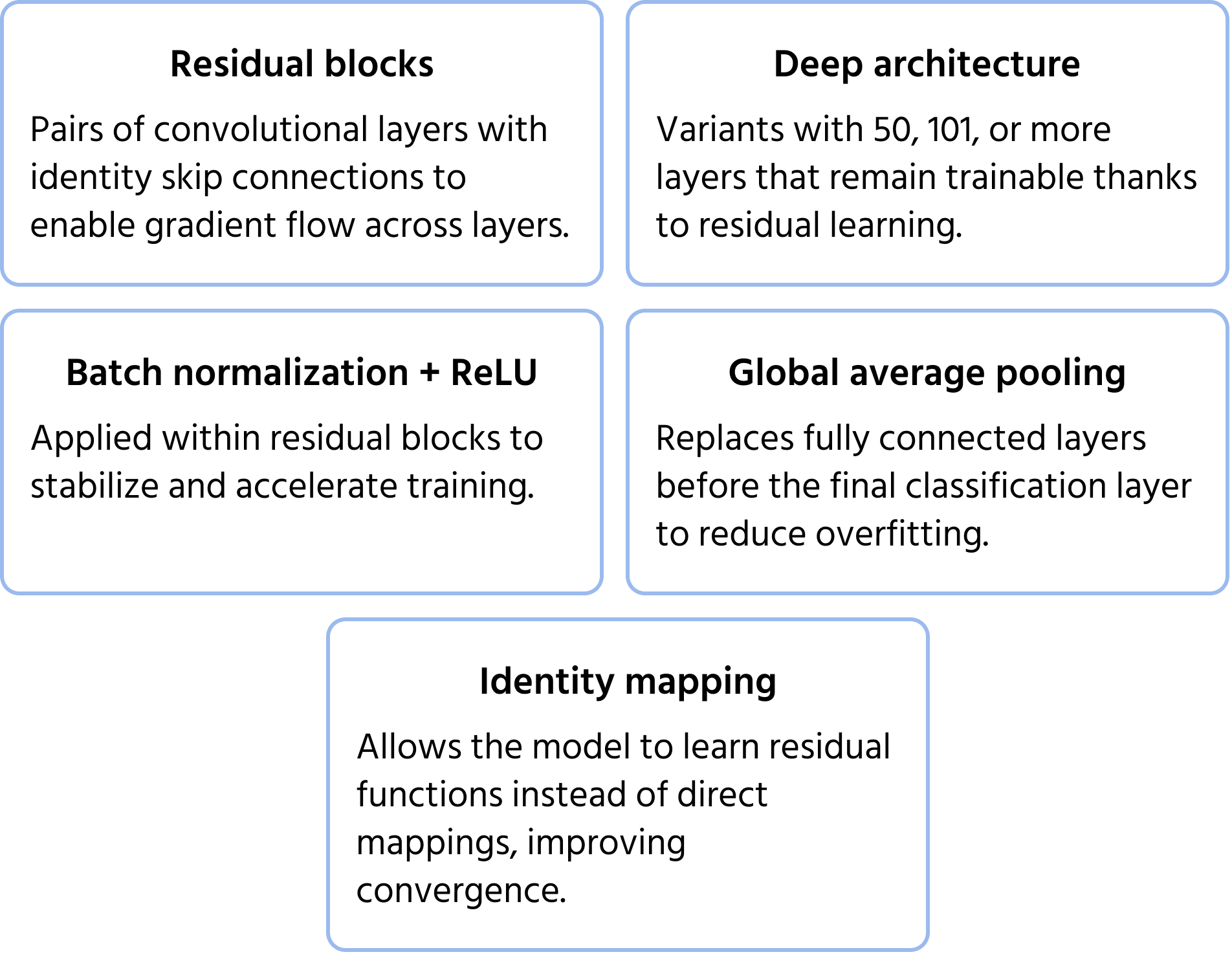
ResNet (Residual Networks), introduced by Microsoft in 2015, addressed the vanishing gradient problem, which occurs when training very deep networks. Traditional deep networks struggle with training efficiency and performance degradation, but ResNet overcame this issue with skip connections (residual learning). These shortcuts allow information to bypass certain layers, ensuring that gradients continue to propagate effectively. ResNet architectures, such as ResNet-50 and ResNet-101, enabled the training of networks with hundreds of layers, significantly improving image classification accuracy. You can learn more about the model in the documentation.
Key Architecture Features
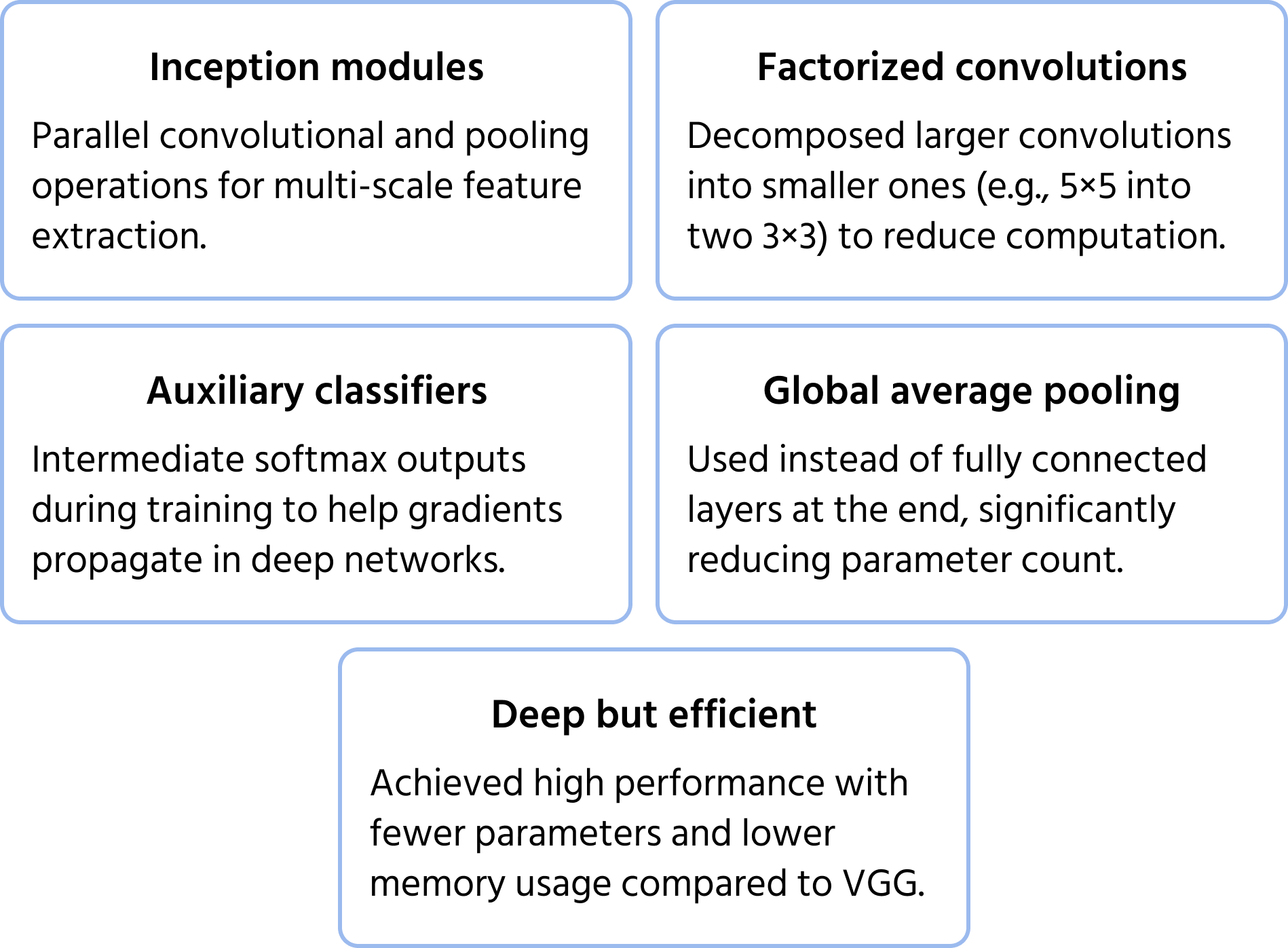
InceptionNet: Multi-Scale Feature Extraction
InceptionNet (also known as GoogLeNet) builds on the inception module to create a deep yet efficient architecture. Instead of stacking layers sequentially, InceptionNet uses parallel paths to extract features at different levels. You can learn more about the model in the documentation.
Key optimizations include:
- Factorized convolutions to reduce computational cost;
- Auxiliary classifiers in intermediate layers to improve training stability;
- Global average pooling instead of fully connected layers, reducing the number of parameters while maintaining performance.
This structure allows InceptionNet to be deeper than previous CNNs like VGG, without drastically increasing computational requirements.
Key Architecture Features
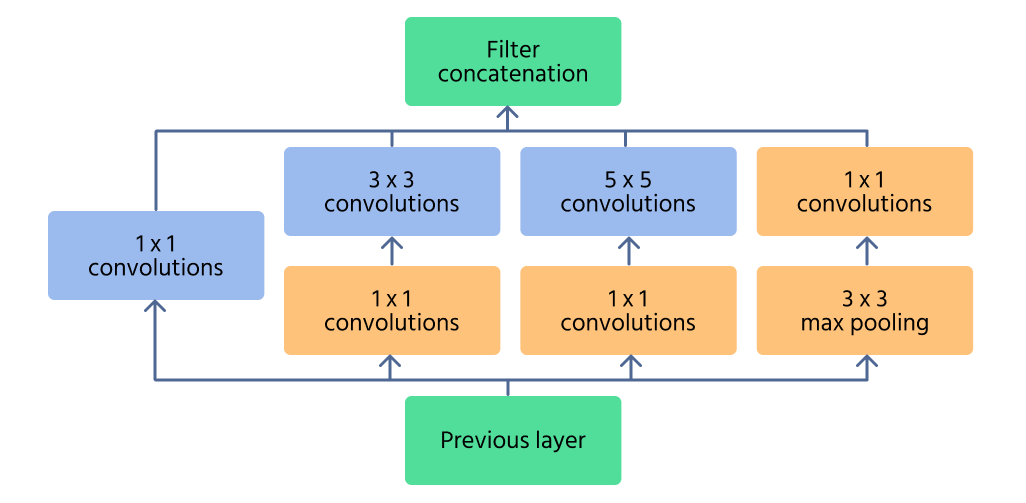
Inception Module
The Inception module is the core component of InceptionNet, designed to efficiently capture features at multiple scales. Instead of applying a single convolution operation, the module processes the input with multiple filter sizes (1×1, 3×3, 5×5) in parallel. This allows the network to recognize both fine details and large patterns in an image.
To reduce computational cost, 1×1 convolutions are used before applying larger filters. These reduce the number of input channels, making the network more efficient. Additionally, max pooling layers within the module help retain essential features while controlling dimensionality.
Example
Consider an example to see how reducing dimensions decreases computational load. Suppose we need to convolve 28 × 28 × 192 input feature maps with 5 × 5 × 32 filters. This operation would require approximately 120.42 million computations.

Number of operations = (2828192) * (5532) = 120.422.400 operations
Let's perform the calculations again, but this time, put a 1×1 convolutional layer before applying the 5×5 convolution to the same input feature maps.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2.408.448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10.035.200 operations
Total number of operations 2.408.448 + 10.035.200 = 12.443.648 operations
Each of these CNN architectures has played a pivotal role in advancing computer vision, influencing applications in healthcare, autonomous systems, security, and real-time image processing. From LeNet's foundational principles to InceptionNet's multi-scale feature extraction, these models have continuously pushed the boundaries of deep learning, paving the way for even more advanced architectures in the future.
1. What was the primary innovation introduced by ResNet that allowed it to train extremely deep networks?
2. How does InceptionNet improve computational efficiency compared to traditional CNNs?
3. Which CNN architecture first introduced the concept of using small 3×3 convolutional filters throughout the network?
Thanks for your feedback!
Ask AI
Ask AI

Ask anything or try one of the suggested questions to begin our chat
