Gated Recurrent Units (GRU)
Swipe to show menu
Definition
Gated recurrent units (GRU) are introduced as a simplified version of LSTMs. GRUs address the same issues as traditional RNNs, such as vanishing gradients, but with fewer parameters, making them faster and more computationally efficient.
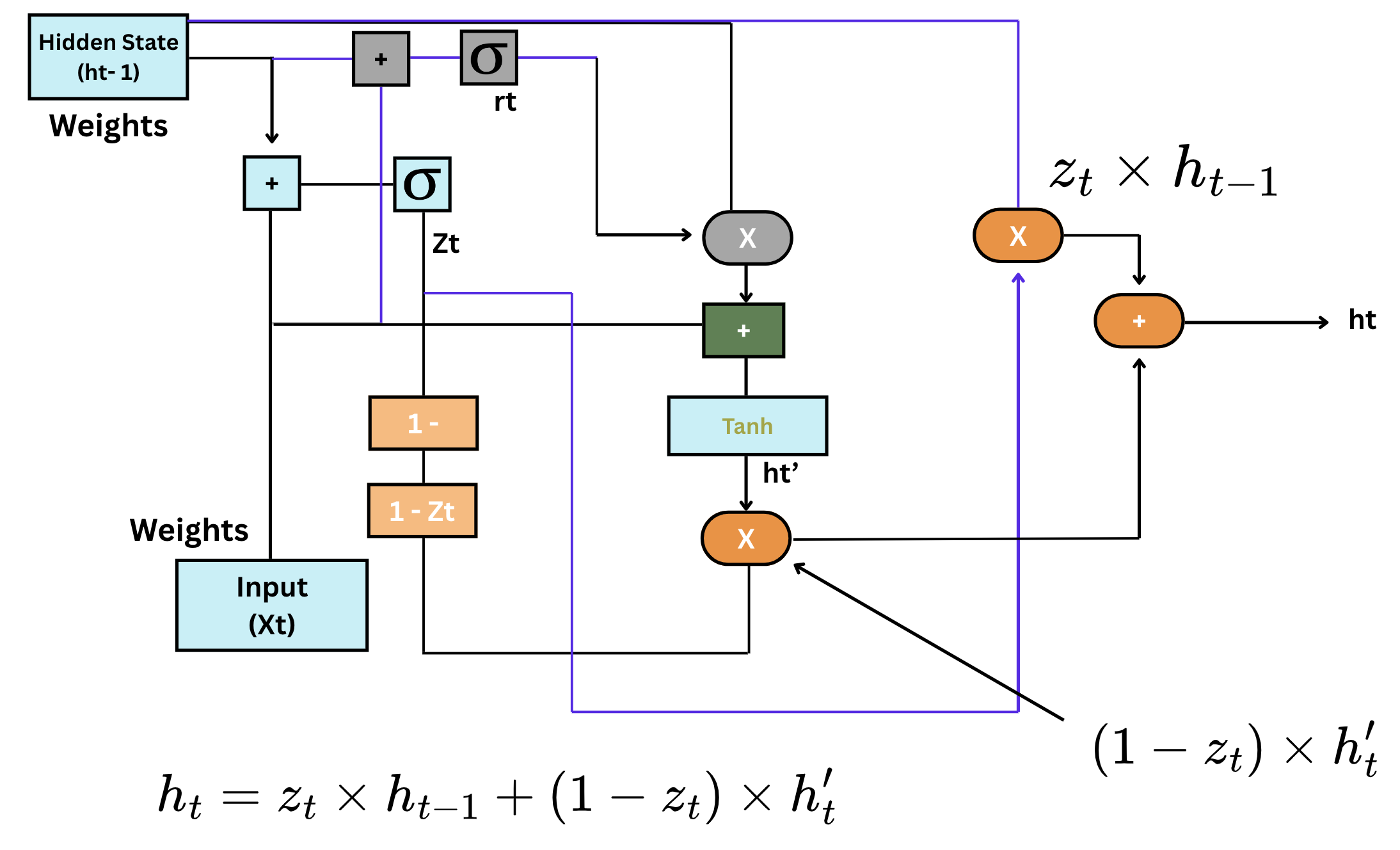
- GRU structure: a GRU has two main components—reset gate and update gate. These gates control the flow of information in and out of the network, similar to LSTM gates but with fewer operations;
- Reset gate: the reset gate determines how much of the previous memory to forget. It outputs a value between 0 and 1, where 0 means "forget" and 1 means "retain";
- Update gate: the update gate decides how much of the new information should be incorporated into the current memory. It helps regulate the model's learning process;
- Advantages of GRUs: GRUs have fewer gates than LSTMs, making them simpler and computationally less expensive. Despite their simpler structure, they often perform just as well as LSTMs on many tasks;
- Applications of GRUs: GRUs are commonly used in applications like speech recognition, language modeling, and machine translation, where the task requires capturing long-term dependencies but without the computational cost of LSTMs.
In summary, GRUs are a more efficient alternative to LSTMs, providing similar performance with a simpler architecture, making them suitable for tasks with large datasets or real-time applications.
Everything was clear?
Thanks for your feedback!
Section 2. Chapter 5
Ask AI
Ask AI

Ask anything or try one of the suggested questions to begin our chat
Section 2. Chapter 5
