Як працює RNN?
Свайпніть щоб показати меню
Рекурентні нейронні мережі (RNN) призначені для обробки послідовних даних шляхом збереження інформації з попередніх входів у своїх внутрішніх станах. Це робить їх ідеальними для завдань, таких як мовне моделювання та прогнозування послідовностей.
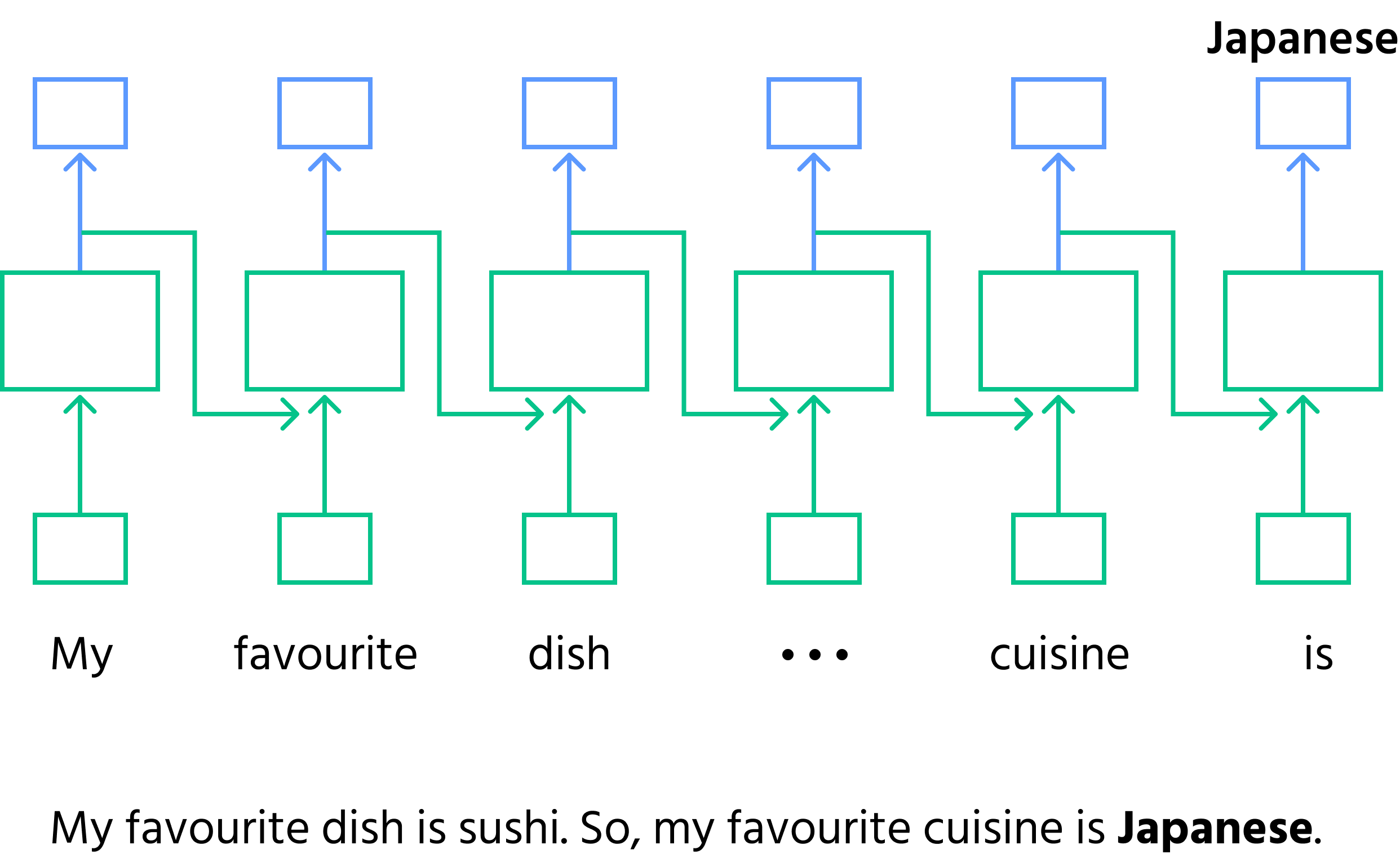
- Послідовна обробка: RNN обробляє дані крок за кроком, відстежуючи попередню інформацію;
- Завершення речення: при незавершеному реченні
"My favourite dish is sushi. So, my favourite cuisine is _____."RNN обробляє слова по черзі. Після слова"sushi"мережа прогнозує наступне слово як"Japanese"на основі попереднього контексту; - Пам'ять у RNN: на кожному кроці RNN оновлює свій внутрішній стан (пам'ять) новою інформацією, забезпечуючи збереження контексту для наступних кроків;
- Навчання RNN: RNN навчаються за допомогою зворотного поширення через час (BPTT), коли помилки передаються назад через кожен часовий крок для коригування ваг з метою покращення прогнозів.
Пряме поширення
Під час прямого поширення RNN обробляє вхідні дані крок за кроком:
-
Вхід на часовому кроці t: мережа отримує вхід xt на кожному часовому кроці;
-
Оновлення прихованого стану: поточний прихований стан ht оновлюється на основі попереднього прихованого стану ht−1 та поточного входу xt за наступною формулою:
- Де:
- W — матриця ваг;
- b — вектор зсуву;
- f — функція активації.
- Де:
-
Генерація виходу: вихід yt генерується на основі поточного прихованого стану ht за формулою:
- Де:
- V — матриця ваг виходу;
- c — зсув виходу;
- g — функція активації, що використовується на вихідному шарі.
- Де:
Процес зворотного поширення
Зворотне поширення в RNN є ключовим для оновлення ваг і покращення моделі. Процес модифікується з урахуванням послідовної природи RNN через зворотне поширення у часі (BPTT):
-
Обчислення помилки: перший крок у BPTT — обчислення помилки на кожному часовому кроці. Зазвичай ця помилка — це різниця між передбаченим виходом і фактичною ціллю;
-
Обчислення градієнта: у рекурентних нейронних мережах градієнти функції втрат обчислюються шляхом диференціювання помилки відносно параметрів мережі та поширюються назад у часі від останнього до початкового кроку, що може призводити до зникнення або вибуху градієнтів, особливо у довгих послідовностях;
-
Оновлення ваг: після обчислення градієнтів ваги оновлюються за допомогою методу оптимізації, такого як стохастичний градієнтний спуск (SGD). Ваги коригуються так, щоб помилка зменшувалася у майбутніх ітераціях. Формула для оновлення ваг:
- Де:
- η — швидкість навчання;
- — градієнт функції втрат відносно матриці ваг.
- Де:
Підсумовуючи, RNN є потужними, оскільки можуть запам'ятовувати та використовувати попередню інформацію, що робить їх придатними для задач, пов'язаних із послідовностями.
Дякуємо за ваш відгук!
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
