Блоки з Керованою Рекурентністю (GRU)
Свайпніть щоб показати меню
Визначення
Gated recurrent units (GRU) представлені як спрощена версія LSTM. GRU вирішують ті ж проблеми, що й традиційні RNN, такі як зникнення градієнтів, але мають менше параметрів, що робить їх швидшими та більш ефективними з обчислювальної точки зору.
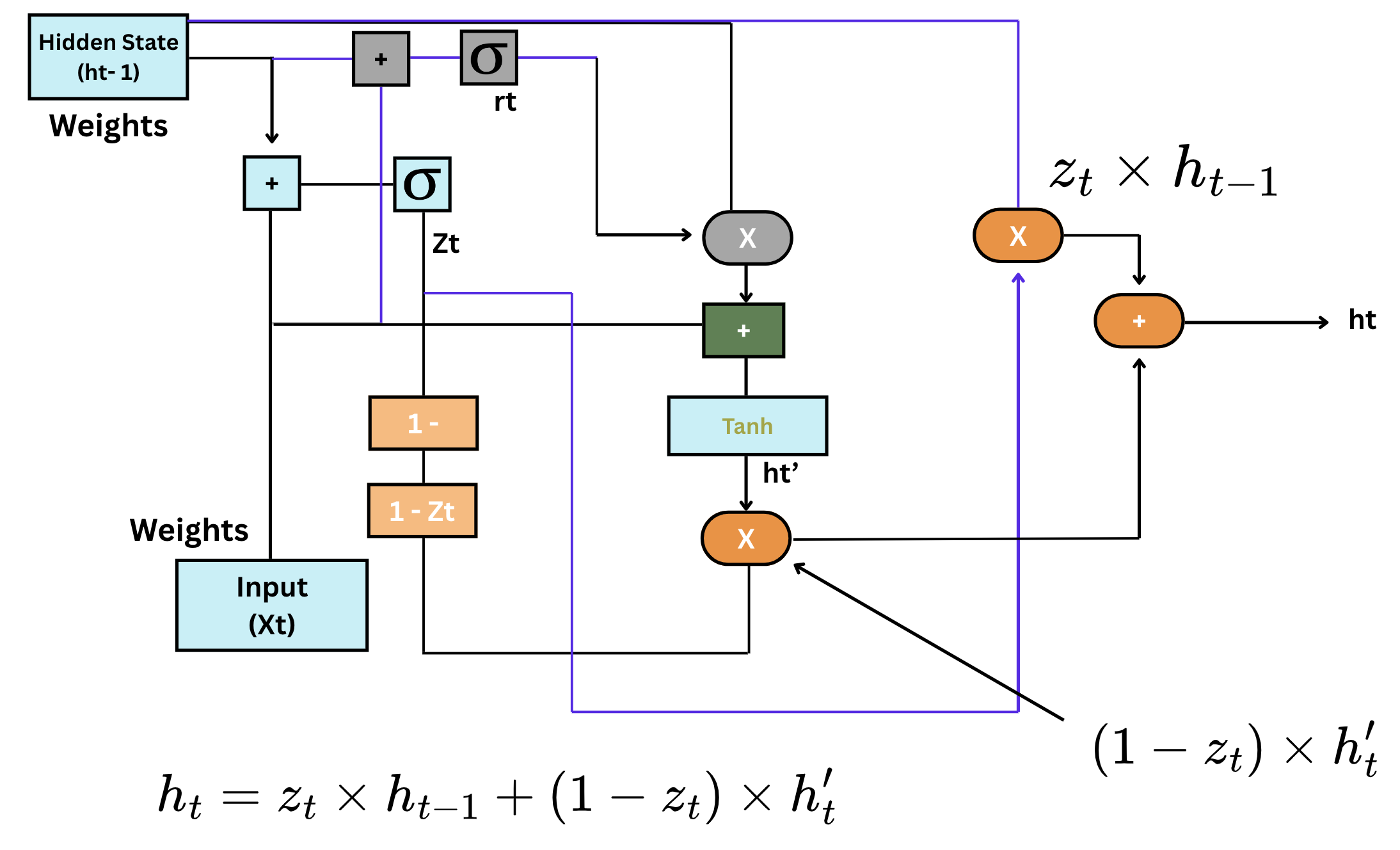
- Структура GRU: GRU має два основних компоненти — reset gate (ворота скидання) та update gate (ворота оновлення). Ці ворота контролюють потік інформації в мережі та з неї, подібно до воріт LSTM, але з меншою кількістю операцій;
- Reset gate: ворота скидання визначають, яку частину попередньої пам'яті слід забути. Вихідне значення знаходиться в межах від 0 до 1, де 0 означає "забути", а 1 — "залишити";
- Update gate: ворота оновлення вирішують, яку частину нової інформації слід включити до поточної пам'яті. Вони допомагають регулювати процес навчання моделі;
- Переваги GRU: GRU мають менше воріт, ніж LSTM, що робить їх простішими та менш затратними з обчислювальної точки зору. Незважаючи на простішу структуру, вони часто демонструють таку ж ефективність, як і LSTM, у багатьох завданнях;
- Застосування GRU: GRU широко використовуються у таких сферах, як розпізнавання мовлення, мовне моделювання та машинний переклад, де необхідно враховувати довгострокові залежності без високих обчислювальних витрат LSTM.
Підсумовуючи, GRU є більш ефективною альтернативою LSTM, забезпечуючи подібну продуктивність із простішою архітектурою, що робить їх придатними для завдань з великими наборами даних або для застосування в реальному часі.
Все було зрозуміло?
Дякуємо за ваш відгук!
Секція 2. Розділ 5
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
Секція 2. Розділ 5
