Генеративні Змагальні Мережі (GANs)
Свайпніть щоб показати меню
Генеративні змагальні мережі (GANs) — це клас генеративних моделей, запропонований Іаном Гудфеллоу у 2014 році. Вони складаються з двох нейронних мереж — Генератора та Дискримінатора, які навчаються одночасно у рамках ігрової теорії. Генератор намагається створювати дані, схожі на реальні, тоді як дискримінатор намагається відрізнити реальні дані від згенерованих.
GAN навчаються генерувати зразки даних із шуму, розв'язуючи задачу мінімакс. У процесі навчання генератор стає кращим у створенні реалістичних даних, а дискримінатор — у розрізненні справжніх і штучних даних.
Архітектура GAN
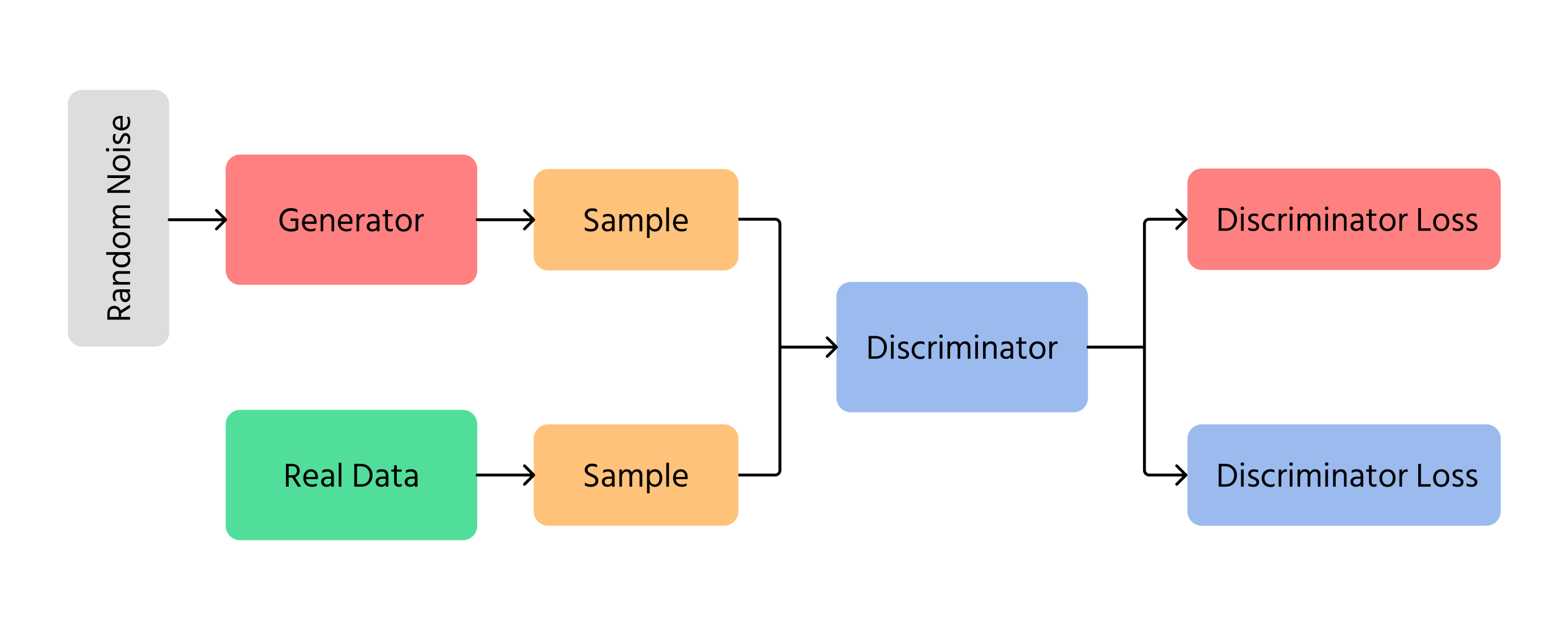
Базова модель GAN складається з двох основних компонентів:
1. Генератор (G)
- Приймає на вхід випадковий вектор шуму z∼pz(z);
- Перетворює його за допомогою нейронної мережі у зразок даних G(z), який має нагадувати дані з істинного розподілу.
2. Дискримінатор (D)
- Приймає або реальний зразок даних x∼px(x), або згенерований зразок G(z);
- Видає скаляр у діапазоні від 0 до 1, що оцінює ймовірність того, що вхід є реальним.
Ці дві компоненти навчаються одночасно. Генератор прагне створювати реалістичні зразки, щоб обдурити дискримінатор, а дискримінатор — правильно розпізнавати реальні та згенеровані зразки.
Мінімаксна гра в GAN
У центрі GAN знаходиться мінімаксна гра, концепція з теорії ігор. У цій схемі:
- Генератор G і дискримінатор D — це конкуруючі гравці;
- D прагне максимізувати свою здатність розрізняти справжні та згенеровані дані;
- G прагне мінімізувати здатність D виявляти його фейкові дані.
Ця динаміка визначає гру з нульовою сумою, де виграш одного гравця є втратою іншого. Оптимізація визначається як:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Генератор намагається обдурити дискримінатор, генеруючи зразки G(z), які максимально наближені до справжніх даних.
Функції втрат
Хоча оригінальна цільова функція GAN визначає мінімаксну гру, на практиці для стабілізації навчання використовуються альтернативні функції втрат.
- Несатурована функція втрат генератора:
Це допомагає генератору отримувати сильні градієнти навіть тоді, коли дискримінатор працює добре.
- Функція втрат дискримінатора:
Ці функції втрат стимулюють генератор створювати зразки, які підвищують невизначеність дискримінатора, і покращують збіжність під час навчання.
Основні варіанти архітектур GAN
З'явилося кілька типів GAN, які покликані вирішити певні обмеження або покращити продуктивність:

Умовна GAN (cGAN)
Умовні GAN розширюють стандартну архітектуру GAN шляхом введення додаткової інформації (зазвичай міток) як у генератор, так і в дискримінатор. Замість генерації даних лише з випадкового шуму, генератор отримує як шум z, так і умову y (наприклад, мітку класу). Дискримінатор також отримує y для оцінки, чи є зразок реалістичним за цієї умови.
- Сфери застосування: генерація зображень з урахуванням класу, трансляція зображення в зображення, генерація зображень за текстовим описом.
Глибока згорткова GAN (DCGAN)
DCGAN замінюють повнозв'язні шари в оригінальних GAN на згорткові та транспоновані згорткові шари, що робить їх ефективнішими для генерації зображень. Також вводяться архітектурні рекомендації, такі як видалення повнозв'язних шарів, використання пакетної нормалізації та застосування активацій ReLU/LeakyReLU.
- Сфери застосування: фотореалістична генерація зображень, навчання візуальних представлень, неконтрольоване навчання ознак.
CycleGAN CycleGAN вирішують проблему непарного перетворення зображень з однієї області в іншу. На відміну від інших моделей, які потребують парних датасетів (наприклад, однакове фото у двох різних стилях), CycleGAN можуть навчатися відображенням між двома доменами без парних прикладів. Вони використовують два генератори та два дискримінатори, кожен з яких відповідає за перетворення в одному напрямку (наприклад, фото в картини і навпаки), і впроваджують втрату циклічної узгодженості (cycle-consistency loss), щоб гарантувати, що перетворення з однієї області і назад повертає оригінальне зображення. Ця втрата є ключовою для збереження змісту та структури.
Втрата циклічної узгодженості гарантує:
GBA(GAB(x))≈x і GAB(GBA(y))≈yде:
- GAB перетворює зображення з домену A в домен B;
- GBA перетворює з домену B в домен A.
- x∈A,y∈B.
Приклади використання: перетворення фото в мистецтво, трансляція зображень коней у зебр, конвертація голосу між мовцями.
StyleGAN
StyleGAN, розроблений компанією NVIDIA, впроваджує стильове керування у генераторі. Замість прямої подачі вектора шуму на генератор, він проходить через мережу відображення для створення "стильових векторів", які впливають на кожен шар генератора. Це дозволяє точно контролювати візуальні характеристики, такі як колір волосся, вираз обличчя чи освітлення.
Важливі інновації:
- Змішування стилів (style mixing), дозволяє комбінувати кілька латентних кодів;
- Адаптивна інстанс-нормалізація (AdaIN), керує картами ознак у генераторі;
- Поступове збільшення роздільної здатності (progressive growing), навчання починається з низької роздільної здатності та поступово збільшується.
Приклади використання: генерація зображень надвисокої роздільної здатності (наприклад, обличчя), керування візуальними атрибутами, створення мистецтва.
Порівняння: GAN проти VAE
GAN — потужний клас генеративних моделей, здатних створювати надзвичайно реалістичні дані завдяки змагальному процесу навчання. Їхня основа — гра мінімакс між двома мережами, які використовують змагальні втрати для поступового вдосконалення обох компонентів. Ґрунтовне розуміння їхньої архітектури, функцій втрат — включаючи варіанти, такі як cGAN, DCGAN, CycleGAN та StyleGAN — і порівняння з іншими моделями, наприклад, VAE, забезпечує необхідну базу для застосування у сферах, таких як генерація зображень, синтез відео, аугментація даних тощо.
1. Яке з наведеного найкраще описує компоненти базової архітектури GAN?
2. Яка мета мінімаксної гри в GANs?
3. Яке з наступних тверджень є правильним щодо різниці між GAN та VAE?
Дякуємо за ваш відгук!
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
