Hoe Werkt een RNN?
Veeg om het menu te tonen
Recurrent neurale netwerken (RNN's) zijn ontworpen om sequentiële data te verwerken door informatie van eerdere invoer op te slaan in hun interne toestanden. Dit maakt ze ideaal voor taken zoals taalmodellering en sequentievoorspelling.
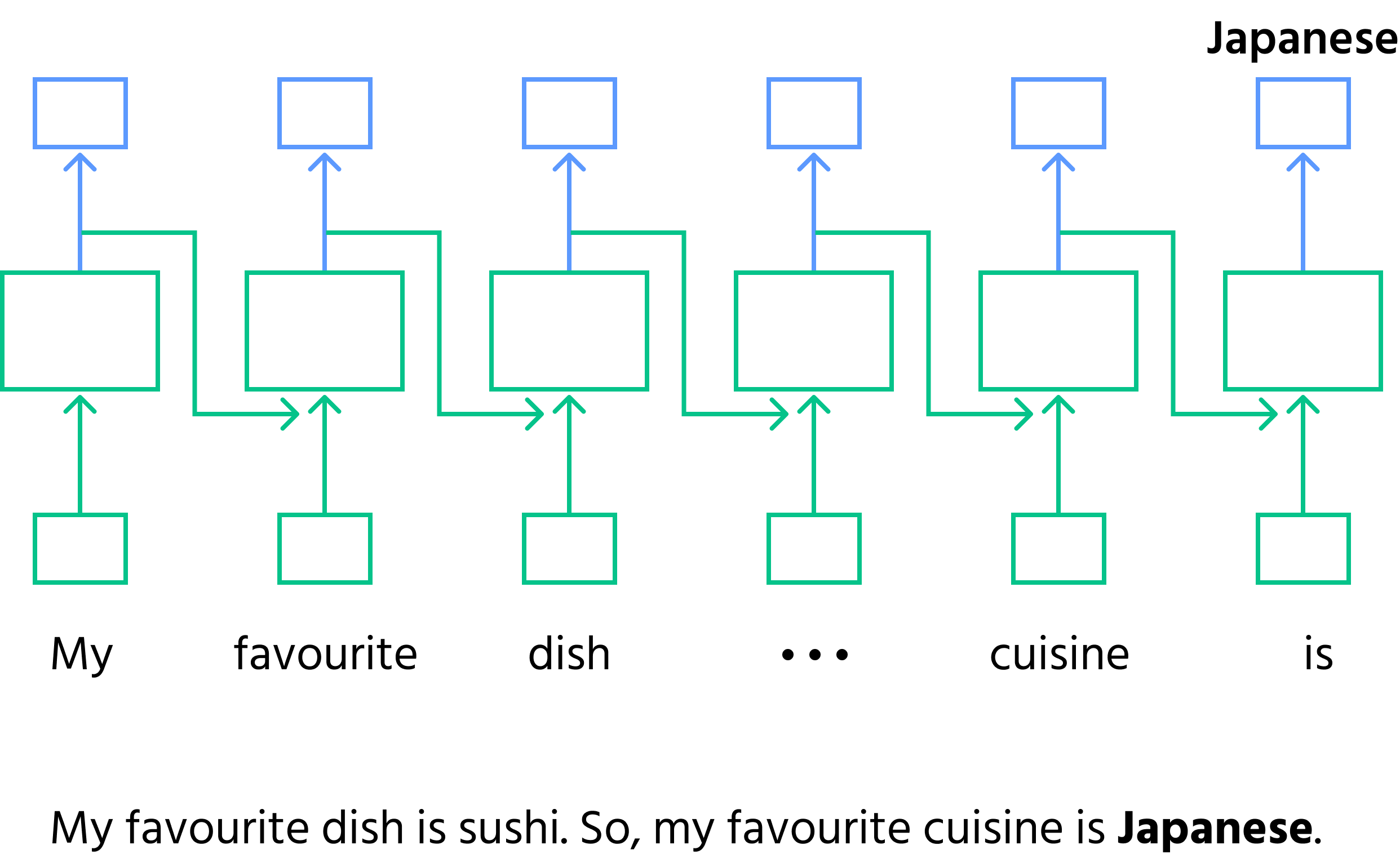
- Sequentiële verwerking: RNN verwerkt data stap voor stap, waarbij wordt bijgehouden wat eerder is gekomen;
- Zin aanvullen: gegeven de onvolledige zin
"My favourite dish is sushi. So, my favourite cuisine is _____."verwerkt de RNN de woorden één voor één. Na het zien van"sushi", voorspelt het het volgende woord als"Japanese"op basis van eerdere context; - Geheugen in RNN's: bij elke stap werkt de RNN zijn interne toestand (geheugen) bij met nieuwe informatie, zodat de context behouden blijft voor toekomstige stappen;
- Training van de RNN: RNN's worden getraind met behulp van backpropagation through time (BPTT), waarbij fouten achterwaarts door elke tijdstap worden doorgegeven om gewichten aan te passen voor betere voorspellingen.
Voorwaartse propagatie
Tijdens de voorwaartse propagatie verwerkt het RNN de invoergegevens stap voor stap:
-
Invoer op tijdstap t: het netwerk ontvangt een invoer xt op elke tijdstap;
-
Update van de verborgen toestand: de huidige verborgen toestand ht wordt bijgewerkt op basis van de vorige verborgen toestand ht−1 en de huidige invoer xt met behulp van de volgende formule:
- Waarbij:
- W de gewichtenmatrix is;
- b de biasvector is;
- f de activatiefunctie is.
- Waarbij:
-
Outputgeneratie: de output yt wordt gegenereerd op basis van de huidige verborgen toestand ht met behulp van de formule:
- Waarbij:
- V de outputgewichtenmatrix is;
- c de outputbias is;
- g de activatiefunctie is die in de outputlaag wordt gebruikt.
- Waarbij:
Backpropagatieproces
Backpropagatie in RNN's is essentieel voor het bijwerken van de gewichten en het verbeteren van het model. Het proces wordt aangepast aan het sequentiële karakter van RNN's via backpropagation through time (BPTT):
-
Foutberekening: de eerste stap in BPTT is het berekenen van de fout op elke tijdstap. Deze fout is doorgaans het verschil tussen de voorspelde output en het werkelijke doel;
-
Gradiëntberekening: in Recurrent Neural Networks worden de gradiënten van de verliesfunctie berekend door de fout te differentiëren ten opzichte van de netwerkparameters en achterwaarts door de tijd te propageren van de laatste naar de eerste stap, wat kan leiden tot verdwijnende of exploderende gradiënten, vooral bij lange reeksen;
-
Gewichtsupdate: zodra de gradiënten zijn berekend, worden de gewichten bijgewerkt met behulp van een optimalisatietechniek zoals stochastic gradient descent (SGD). De gewichten worden zo aangepast dat de fout in toekomstige iteraties wordt geminimaliseerd. De formule voor het bijwerken van gewichten is:
- Waarbij:
- η de leersnelheid is;
- de gradiënt van de verliesfunctie ten opzichte van de gewichtenmatrix is.
- Waarbij:
Samengevat zijn RNN's krachtig omdat ze informatie uit het verleden kunnen onthouden en gebruiken, waardoor ze geschikt zijn voor taken die reeksen omvatten.
Bedankt voor je feedback!
Vraag AI
Vraag AI

Vraag wat u wilt of probeer een van de voorgestelde vragen om onze chat te starten.
