Comment Fonctionnent les RNN ?
Glissez pour afficher le menu
Les réseaux de neurones récurrents (RNN) sont conçus pour traiter des données séquentielles en conservant l'information des entrées précédentes dans leurs états internes. Cela les rend idéaux pour des tâches telles que la modélisation du langage et la prédiction de séquences.
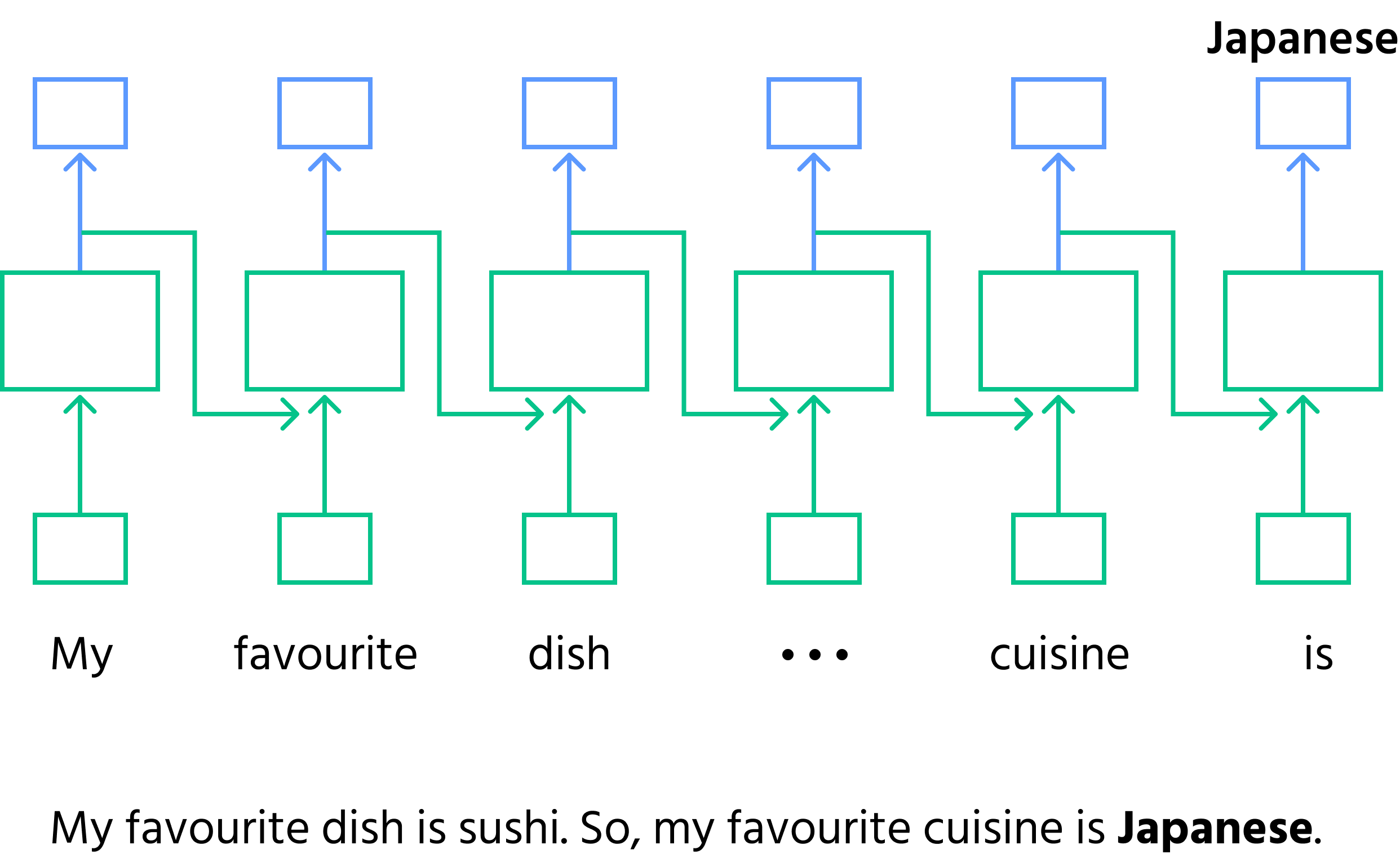
- Traitement séquentiel : le RNN traite les données étape par étape, en gardant une trace de ce qui a précédé ;
- Complétion de phrase : étant donné la phrase incomplète
"My favourite dish is sushi. So, my favourite cuisine is _____."le RNN traite les mots un par un. Après avoir vu"sushi", il prédit le mot suivant comme étant"Japanese"en se basant sur le contexte précédent ; - Mémoire dans les RNN : à chaque étape, le RNN met à jour son état interne (mémoire) avec de nouvelles informations, garantissant ainsi la conservation du contexte pour les étapes futures ;
- Entraînement du RNN : les RNN sont entraînés à l'aide de la rétropropagation dans le temps (BPTT), où les erreurs sont propagées en arrière à travers chaque étape temporelle afin d'ajuster les poids pour de meilleures prédictions.
Propagation avant
Lors de la propagation avant, le RNN traite les données d'entrée étape par étape :
-
Entrée à l'instant t : le réseau reçoit une entrée xt à chaque instant ;
-
Mise à jour de l'état caché : l'état caché actuel ht est mis à jour en fonction de l'état caché précédent ht−1 et de l'entrée actuelle xt selon la formule suivante :
- Où :
- W est la matrice de poids ;
- b est le vecteur de biais ;
- f est la fonction d'activation.
- Où :
-
Génération de la sortie : la sortie yt est générée à partir de l'état caché actuel ht selon la formule :
- Où :
- V est la matrice de poids de sortie ;
- c est le biais de sortie ;
- g est la fonction d'activation utilisée à la couche de sortie.
- Où :
Processus de rétropropagation
La rétropropagation dans les RNN est essentielle pour la mise à jour des poids et l'amélioration du modèle. Le processus est adapté pour prendre en compte la nature séquentielle des RNN via la rétropropagation dans le temps (BPTT) :
-
Calcul de l'erreur : la première étape de la BPTT consiste à calculer l'erreur à chaque instant. Cette erreur correspond généralement à la différence entre la sortie prédite et la cible réelle ;
-
Calcul du gradient : dans les réseaux de neurones récurrents, les gradients de la fonction de perte sont calculés en différenciant l'erreur par rapport aux paramètres du réseau et sont propagés en arrière dans le temps de l'étape finale à l'étape initiale, ce qui peut entraîner des gradients qui disparaissent ou explosent, en particulier pour les longues séquences ;
-
Mise à jour des poids : une fois les gradients calculés, les poids sont mis à jour à l'aide d'une technique d'optimisation telle que la descente de gradient stochastique (SGD). Les poids sont ajustés de manière à minimiser l'erreur lors des itérations futures. La formule de mise à jour des poids est :
- Où :
- η est le taux d'apprentissage ;
- est le gradient de la fonction de perte par rapport à la matrice de poids.
- Où :
En résumé, les RNN sont puissants car ils peuvent mémoriser et exploiter des informations passées, ce qui les rend adaptés aux tâches impliquant des séquences.
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
