Miten RNN Toimii?
Pyyhkäise näyttääksesi valikon
Toistuvat neuroverkot (RNN:t) on suunniteltu käsittelemään sekventiaalista dataa säilyttämällä tietoa aiemmista syötteistä niiden sisäisissä tiloissa. Tämä tekee niistä ihanteellisia tehtäviin kuten kielimallinnus ja sekvenssien ennustaminen.
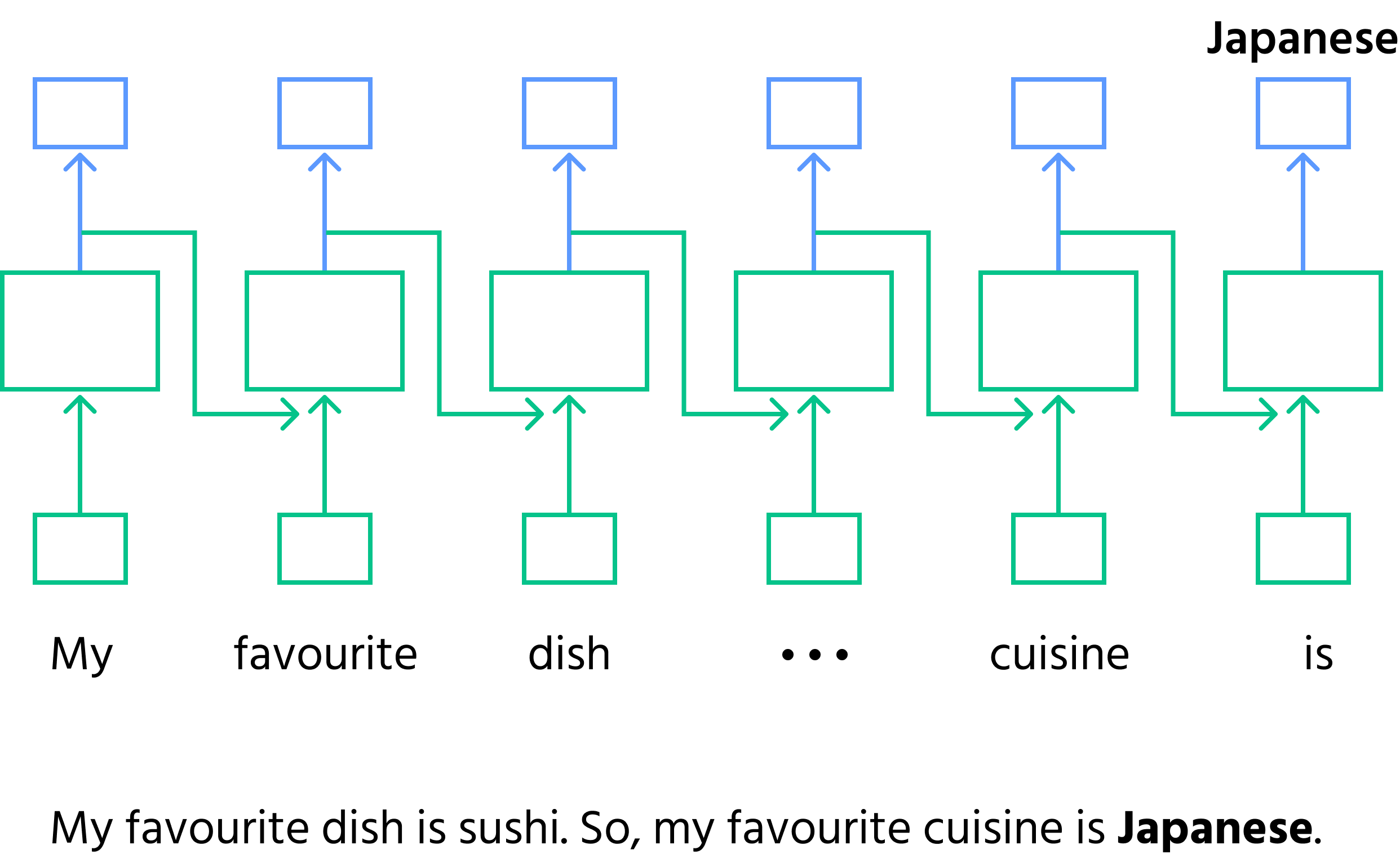
- Sekventiaalinen käsittely: RNN käsittelee dataa askel askeleelta, pitäen kirjaa aiemmasta;
- Lauseen täydentäminen: kun annetaan keskeneräinen lause
"My favourite dish is sushi. So, my favourite cuisine is _____.", RNN käsittelee sanat yksi kerrallaan. Nähdessään sanan"sushi", se ennustaa seuraavaksi sanaksi"Japanese"aiemman kontekstin perusteella; - Muisti RNN:issä: jokaisessa vaiheessa RNN päivittää sisäistä tilaansa (muistia) uudella tiedolla, varmistaen kontekstin säilymisen tulevia askeleita varten;
- RNN:n koulutus: RNN:t koulutetaan käyttäen takaisinkytkentää ajan yli (BPTT), jossa virheet kulkevat taaksepäin jokaisen aikavaiheen läpi painojen säätämiseksi parempia ennusteita varten.
Eteenpäinlevitys
Eteenpäinlevityksen aikana RNN käsittelee syötteen vaihe vaiheelta:
-
Syöte ajanhetkellä t: verkko vastaanottaa syötteen xt jokaisella ajanhetkellä;
-
Piilotilan päivitys: nykyinen piilotila ht päivitetään edellisen piilotilan ht−1 ja nykyisen syötteen xt perusteella seuraavan kaavan mukaisesti:
- Missä:
- W on painomatriisi;
- b on bias-vektori;
- f on aktivointifunktio.
- Missä:
-
Ulostulon muodostus: ulostulo yt muodostetaan nykyisen piilotilan ht perusteella seuraavan kaavan mukaisesti:
- Missä:
- V on ulostulon painomatriisi;
- c on ulostulon bias;
- g on ulostulokerroksen aktivointifunktio.
- Missä:
Takaisinkytkentäprosessi
Takaisinkytkentä (backpropagation) on olennainen RNN:ien painojen päivittämisessä ja mallin parantamisessa. Prosessia muokataan RNN:ien jaksollisen luonteen vuoksi käyttämällä aikaan ulottuvaa takaisinkytkentää (BPTT, Backpropagation Through Time):
-
Virheen laskenta: BPTT:n ensimmäinen vaihe on laskea virhe jokaisella ajanhetkellä. Tämä virhe on tyypillisesti ennustetun ulostulon ja todellisen tavoitteen välinen ero;
-
Gradientin laskenta: Toistoverkoissa (Recurrent Neural Networks) tappiofunktion gradientit lasketaan derivoimalla virhe verkon parametrien suhteen ja propagaatio tapahtuu ajassa taaksepäin viimeisestä vaiheesta alkuun. Tämä voi johtaa katoaviin tai räjähtäviin gradientteihin erityisesti pitkissä sekvensseissä;
-
Painojen päivitys: Kun gradientit on laskettu, painot päivitetään käyttämällä optimointimenetelmää, kuten stokastista gradienttilaskeutumista (SGD). Painoja säädetään siten, että virhe pienenee tulevissa iteraatioissa. Painojen päivityksen kaava on:
- Missä:
- η on oppimisnopeus;
- on tappiofunktion gradientti painomatriisin suhteen.
- Missä:
Yhteenvetona: RNN:t ovat tehokkaita, koska ne voivat muistaa ja hyödyntää aiempaa tietoa, mikä tekee niistä sopivia tehtäviin, joissa käsitellään sekvenssejä.
Kiitos palautteestasi!
Kysy tekoälyä
Kysy tekoälyä

Kysy mitä tahansa tai kokeile jotakin ehdotetuista kysymyksistä aloittaaksesi keskustelumme
