Gated Recurrent -Yksiköt (GRU)
Pyyhkäise näyttääksesi valikon
Määritelmä
Gated recurrent units (GRU) on esitelty LSTM-verkkojen yksinkertaistettuna versiona. GRU:t ratkaisevat samoja ongelmia kuin perinteiset RNN:t, kuten katoavat gradientit, mutta niissä on vähemmän parametreja, mikä tekee niistä nopeampia ja laskennallisesti tehokkaampia.
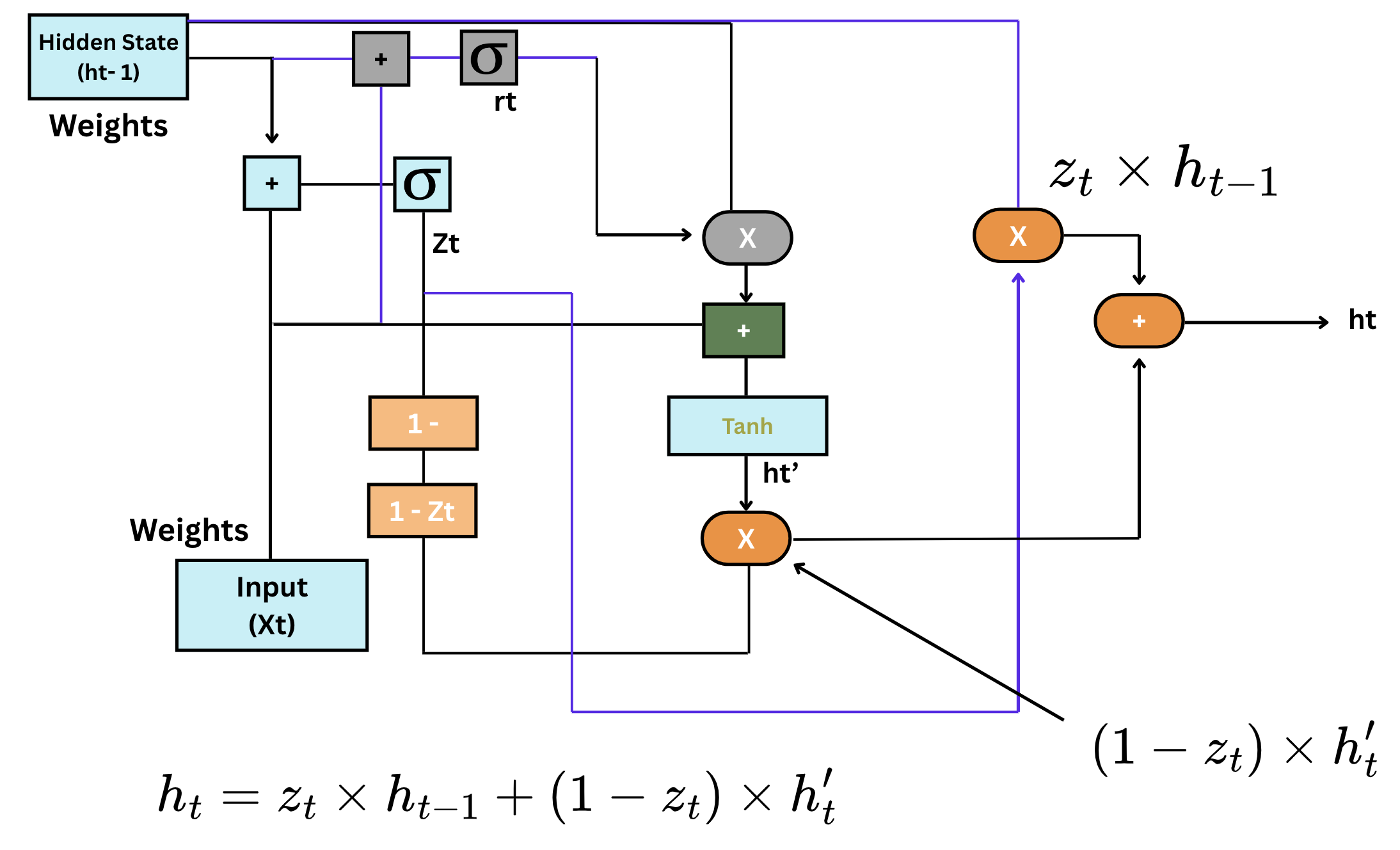
- GRU:n rakenne: GRU:ssa on kaksi pääkomponenttia—reset gate (nollausportti) ja update gate (päivitysportti). Nämä portit säätelevät tiedon kulkua verkkoon ja sieltä pois, samankaltaisesti kuin LSTM-portit, mutta vähemmillä operaatioilla;
- Reset gate: nollausportti määrittää, kuinka paljon aiemmasta muistista unohdetaan. Se tuottaa arvon välillä 0 ja 1, missä 0 tarkoittaa "unohda" ja 1 "säilytä";
- Update gate: päivitysportti päättää, kuinka paljon uutta tietoa sisällytetään nykyiseen muistiin. Se auttaa säätelemään mallin oppimisprosessia;
- GRU:n edut: GRU:ssa on vähemmän portteja kuin LSTM:ssä, mikä tekee siitä yksinkertaisemman ja laskennallisesti kevyemmän. Yksinkertaisemmasta rakenteestaan huolimatta GRU:t suoriutuvat usein yhtä hyvin kuin LSTM:t monissa tehtävissä;
- GRU:n käyttökohteet: GRU:ita käytetään yleisesti sovelluksissa kuten puheentunnistus, kielimallinnus ja konekäännös, joissa tehtävä vaatii pitkän aikavälin riippuvuuksien mallintamista ilman LSTM:ien laskennallista kuormitusta.
Yhteenvetona voidaan todeta, että GRU:t ovat tehokkaampi vaihtoehto LSTM:ille, tarjoten samanlaista suorituskykyä yksinkertaisemmalla arkkitehtuurilla. Tämä tekee niistä sopivia tehtäviin, joissa on suuria tietoaineistoja tai reaaliaikaisia sovelluksia.
Oliko kaikki selvää?
Kiitos palautteestasi!
Osio 2. Luku 5
Kysy tekoälyä
Kysy tekoälyä

Kysy mitä tahansa tai kokeile jotakin ehdotetuista kysymyksistä aloittaaksesi keskustelumme
Osio 2. Luku 5
