Sección 1. Capítulo 7
single
February vs July Average Temperatures
Desliza para mostrar el menú
Well, as you remember, there are no 100% correct answers to clustering problems. For the last task you solved it seems like 5 clusters might be a good option.
Let's visualize the results of clustering into 5 groups by building the scatter plot for average February vs July temperatures, which are one of the coldest and hottest months respectively.
Tarea
Desliza para comenzar a programar
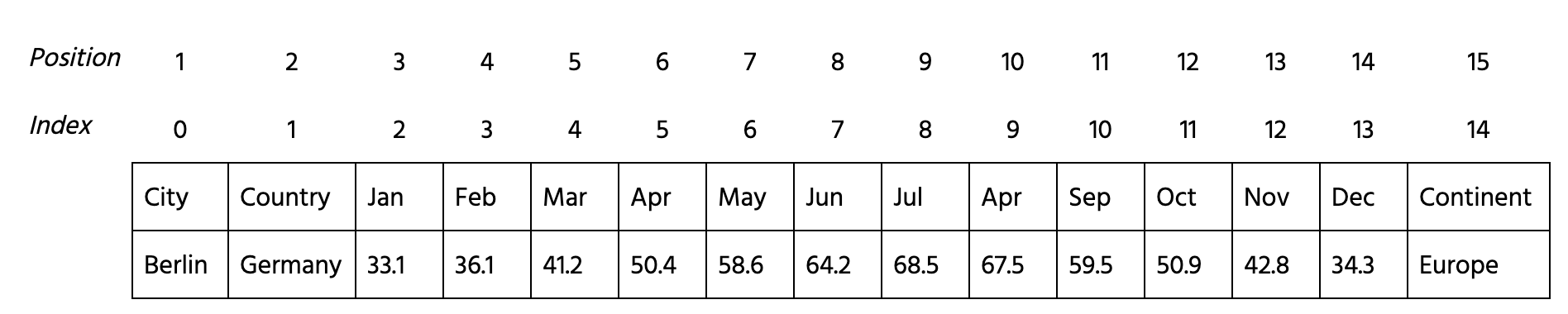
- Create a
KMeansmodel namedmodelwith 5 clusters. - Fit the numerical columns of
data(2 - 13 indices) tomodel. - Add the
'prediction'column to thedataDataFrame with predicted bymodellabels. - Build a scatter plot of average
'Feb'vs'Jul'temperatures, having each point colored with respect to the'prediction'column of thedataDataFrame.
Solución
¿Todo estuvo claro?
¡Gracias por tus comentarios!
Sección 1. Capítulo 7
single
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
