Hvordan Fungerer RNN?
Stryg for at vise menuen
Rekursive neurale netværk (RNN'er) er designet til at håndtere sekventielle data ved at bevare information fra tidligere input i deres interne tilstande. Dette gør dem ideelle til opgaver som sproglig modellering og sekvensforudsigelse.
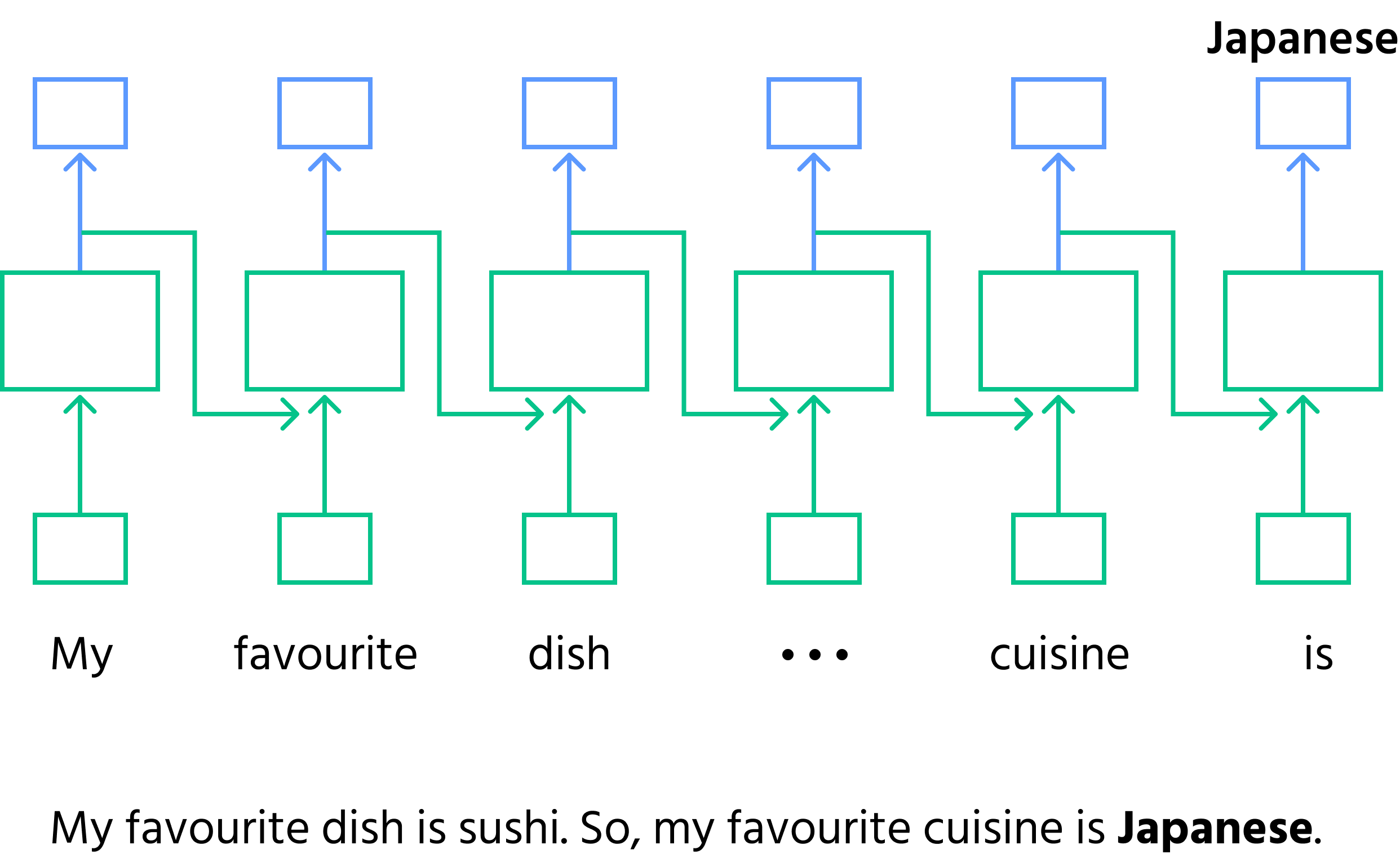
- Sekventiel behandling: RNN behandler data trin for trin og holder styr på, hvad der er kommet før;
- Sætningsfuldførelse: givet den ufuldstændige sætning
"My favourite dish is sushi. So, my favourite cuisine is _____."behandler RNN ordene én ad gangen. Efter at have set"sushi", forudsiger den det næste ord som"Japanese"baseret på tidligere kontekst; - Hukommelse i RNN'er: ved hvert trin opdaterer RNN sin interne tilstand (hukommelse) med ny information, hvilket sikrer, at den bevarer konteksten til fremtidige trin;
- Træning af RNN: RNN'er trænes ved hjælp af backpropagation through time (BPTT), hvor fejl sendes baglæns gennem hvert tidssteg for at justere vægte for bedre forudsigelser.
Fremadrettet Propagering
Under fremadrettet propagering behandler RNN inputdata trin for trin:
-
Input ved tidssteg t: netværket modtager et input xt ved hvert tidssteg;
-
Opdatering af skjult tilstand: den nuværende skjulte tilstand ht opdateres baseret på den forrige skjulte tilstand ht−1 og det nuværende input xt ved hjælp af følgende formel:
- Hvor:
- W er vægtmatricen;
- b er biasvektoren;
- f er aktiveringsfunktionen.
- Hvor:
-
Outputgenerering: outputtet yt genereres baseret på den nuværende skjulte tilstand ht ved hjælp af formlen:
- Hvor:
- V er outputvægtmatricen;
- c er outputbias;
- g er aktiveringsfunktionen brugt i outputlaget.
- Hvor:
Tilbagepropageringsproces
Tilbagepropagering i RNN'er er afgørende for at opdatere vægtene og forbedre modellen. Processen er tilpasset for at tage højde for den sekventielle karakter af RNN'er gennem tilbagepropagering gennem tid (BPTT):
-
Fejlberegning: det første trin i BPTT er at beregne fejlen ved hvert tidssteg. Denne fejl er typisk forskellen mellem det forudsagte output og det faktiske mål;
-
Gradientberegning: i rekurrente neurale netværk beregnes gradienterne af tabfunktionen ved at differentiere fejlen med hensyn til netværkets parametre og propageres bagud gennem tiden fra det sidste til det første trin, hvilket kan føre til forsvindende eller eksploderende gradienter, især i lange sekvenser;
-
Vægtopdatering: når gradienterne er beregnet, opdateres vægtene ved hjælp af en optimeringsteknik som stokastisk gradientnedstigning (SGD). Vægtene justeres således, at fejlen minimeres i fremtidige iterationer. Formlen for opdatering af vægte er:
- Hvor:
- η er indlæringsraten;
- er gradienten af tabfunktionen med hensyn til vægtmatricen.
- Hvor:
Sammenfattende er RNN'er kraftfulde, fordi de kan huske og udnytte tidligere information, hvilket gør dem velegnede til opgaver, der involverer sekvenser.
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
