Gated Recurrent Units (GRU)
Stryg for at vise menuen
Definition
Gated recurrent units (GRU) introduceres som en forenklet version af LSTM'er. GRU'er adresserer de samme problemer som traditionelle RNN'er, såsom forsvindende gradienter, men med færre parametre, hvilket gør dem hurtigere og mere beregningseffektive.
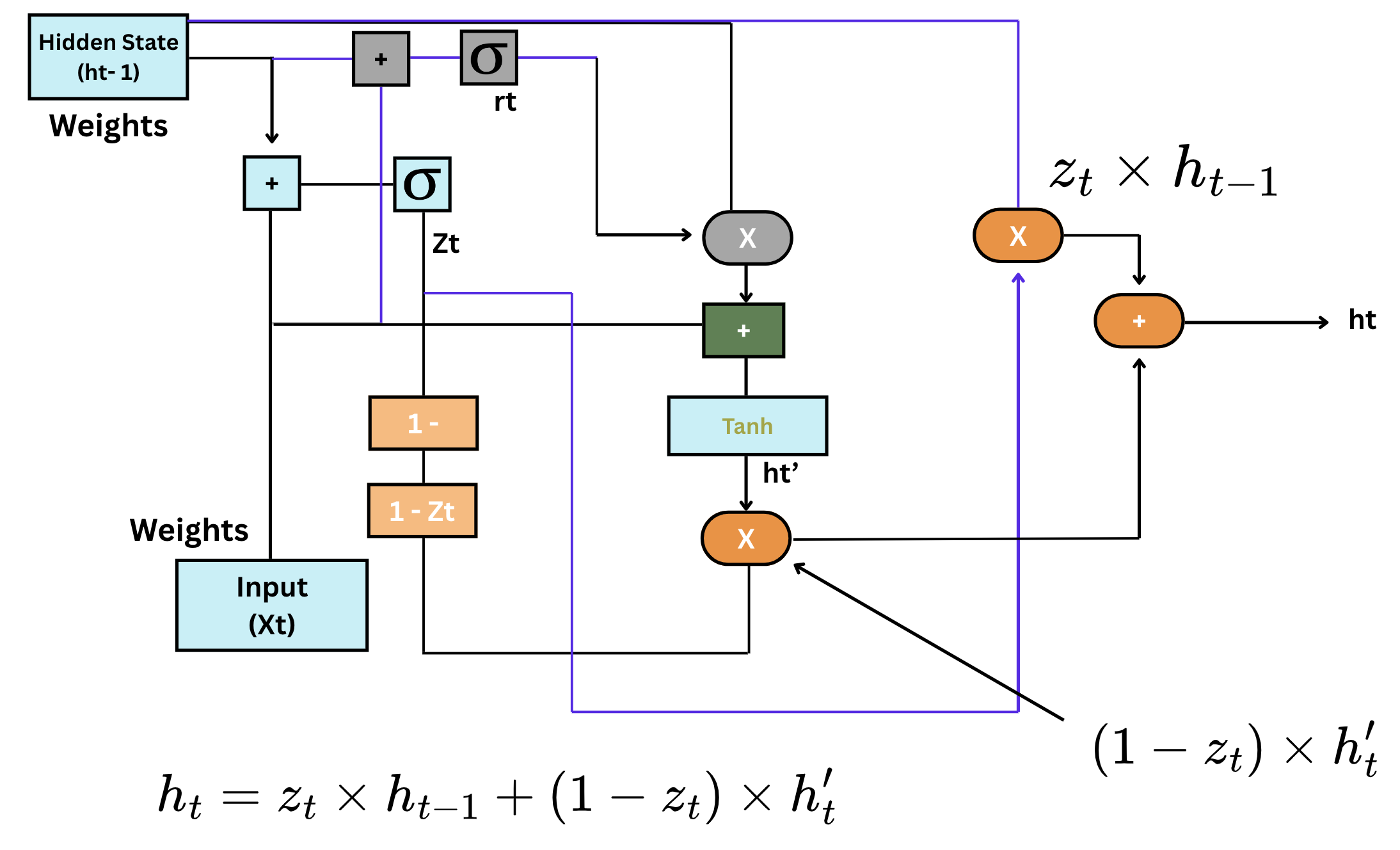
- GRU-struktur: En GRU har to hovedkomponenter—reset gate og update gate. Disse gates styrer informationsflowet ind og ud af netværket, svarende til LSTM-gates, men med færre operationer;
- Reset gate: Reset-gaten bestemmer, hvor meget af den tidligere hukommelse der skal glemmes. Den returnerer en værdi mellem 0 og 1, hvor 0 betyder "glem" og 1 betyder "behold";
- Update gate: Update-gaten afgør, hvor meget af den nye information der skal inkorporeres i den aktuelle hukommelse. Den hjælper med at regulere modellens læringsproces;
- Fordele ved GRU'er: GRU'er har færre gates end LSTM'er, hvilket gør dem enklere og mindre beregningstunge. På trods af deres enklere struktur præsterer de ofte lige så godt som LSTM'er på mange opgaver;
- Anvendelser af GRU'er: GRU'er anvendes ofte i applikationer som talegenkendelse, sproglig modellering og maskinoversættelse, hvor opgaven kræver at fange langtidshukommelse uden den beregningsmæssige omkostning ved LSTM'er.
Sammenfattende er GRU'er et mere effektivt alternativ til LSTM'er, da de leverer tilsvarende ydeevne med en enklere arkitektur, hvilket gør dem velegnede til opgaver med store datasæt eller realtidsapplikationer.
Var alt klart?
Tak for dine kommentarer!
Sektion 2. Kapitel 5
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
Sektion 2. Kapitel 5
